腾讯发最绽开源MoE模子,3890亿参数免费可商用,跑分超Llama3.1
发布日期:2024-11-07 05:58 点击次数:91梦晨 发自 凹非寺
量子位 | 公众号 QbitAI腾讯拿出看家才能,来挤开源赛说念,一刹发布了市面上最大的开源MoE模子。
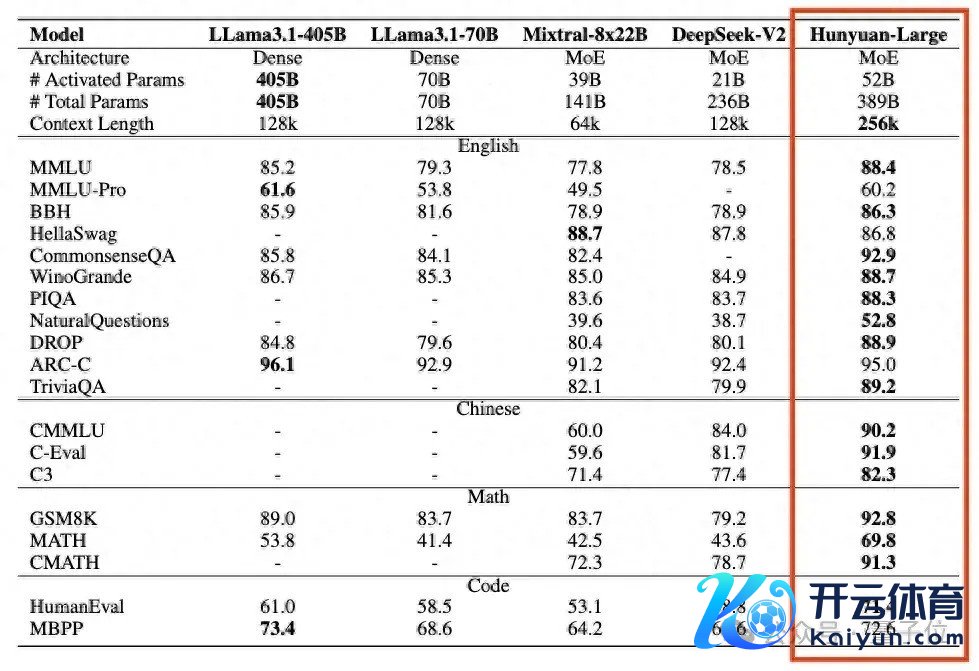
Hunyuan-Large,3890亿总参数,520亿激活参数。
跑分卓越Llama 3.1 405B等开源旗舰,高下文长度维持也跳动一档来到256k。
诚然Hunyuan-Large还不算腾讯里面的旗舰模子,但腾讯先容底层时代与混元大模子“同宗同源”:
许多细节都是里面业务打磨好再开源出来的,比如用到了腾讯元宝App的AI长文阅读等功能里。
当今这么的一个模子透顶开源,免费可商用,算是很有诚意了。

此次腾讯Hunyuan-Large总计开源了三个版块:预考研模子、微调模子、FP8量化的微调模子。
在开源社区掀翻一阵热议,HuggingFace首席科学家Thomas Wolf墙裂保举并追念了几个亮点。
数学才略很强用了许多悉心制作的合成数据真切探索了MoE考研,使用分享巨匠、追念了MoE的Scaling Law。
各路开发者中,有立马运转下载部署的源流派,也有东说念主但愿腾讯入局后,开源模子卷起来能迫使Meta造出更好的模子。
此次腾讯同步发布了时代阐发,其中许多时代细节也引起决议。
如计较了MoE的Scaling Law公式,C ≈ 9.59ND + 2.3 ×108D。
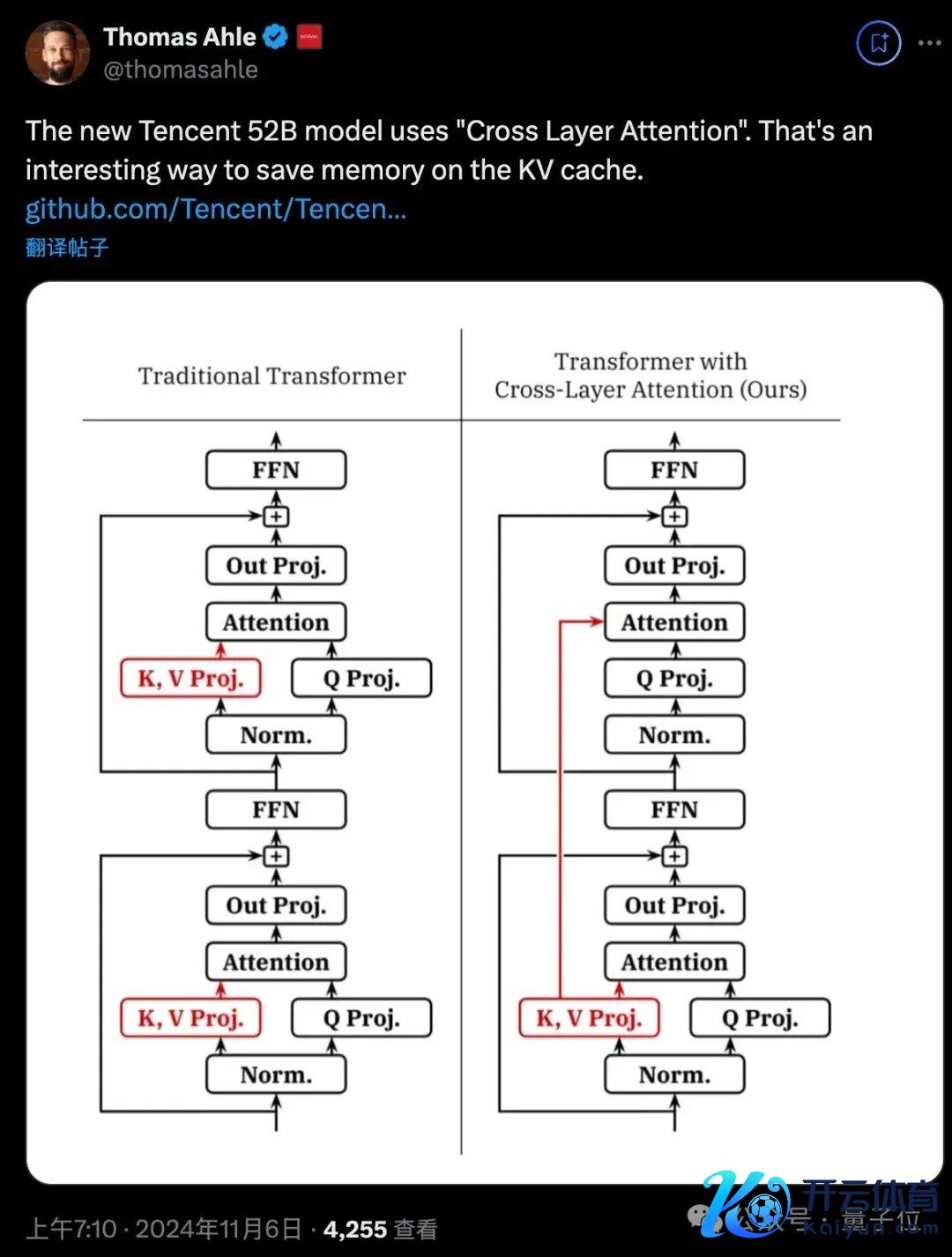
又比如用交叉层驻防力省俭KV缓存的内存占用。
底下奉上发布会现场演宣战时代阐发精华内容追念。
Hunyuan-Large时代阐发MoE的Scaling Law胜仗上公式:
C ≈ 9.59ND + 2.3 × 108D
其中C暗示计较预算(单元FLOPs),N暗示激活参数数目,D暗示考研数据量(单元tokens)。
与传统密集模子的计较预算公式C=6ND比拟,MoE模子公式的各别主要体当今两个方面:
一是系数从6增多到9.59,反馈了MoE零碎的路由计较支拨,包含巨匠切换的计较老本。
二是增多了常数项2.3×108D,反馈了长序列MoE模子attention计较的零碎支拨。
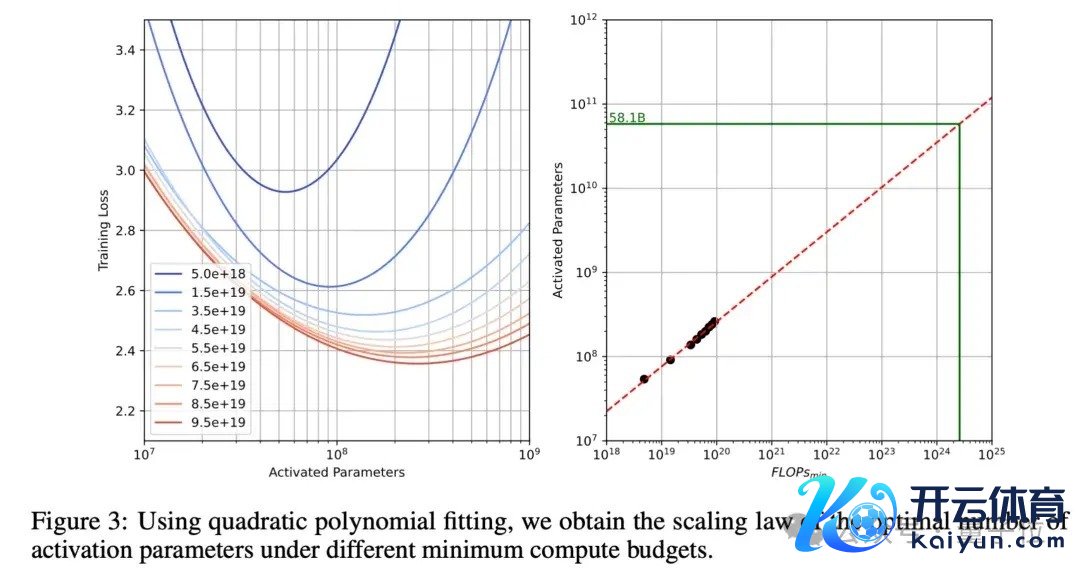
为了细目最优激活参数目,团队进入广泛老本伸开实验:
考研一系列激活参数范围从10M到1B的模子,使用最高1000亿tokens的考研数据,遮蔽100亿到1000亿tokens的不同数据界限。
使用isoFLOPs弧线,在固定计较预算下寻找最优点,同期谈判本色考研batch size的影响,分析不同参数目和数据量的组合,计较得出最优激活参数目约为58.1B。
而最终Hunyuan-Large采选了52B的激活参数目,主要谈判到最优点隔壁弧线平滑,在58.1B隔壁有较大容差空间,以及计较资源照管、考研稳固性要乞降部署效果平衡等推行身分。
路由和考研战略
除了揭秘最优参数配比,时代阐发中还详解了Hunyuan-Large特有的”MoE心法”。
夹杂路由战略:
Hunyuan-Large接受分享巨匠(shared expert)和荒谬巨匠(specialized experts)相蚁合的夹杂路由。
每个token激活1个分享巨匠和1个成心巨匠,分享巨匠贬责系数token的通用常识,而荒谬巨匠则用top-k路由战略动态激活,崇敬贬包袱务联系的荒谬才略。
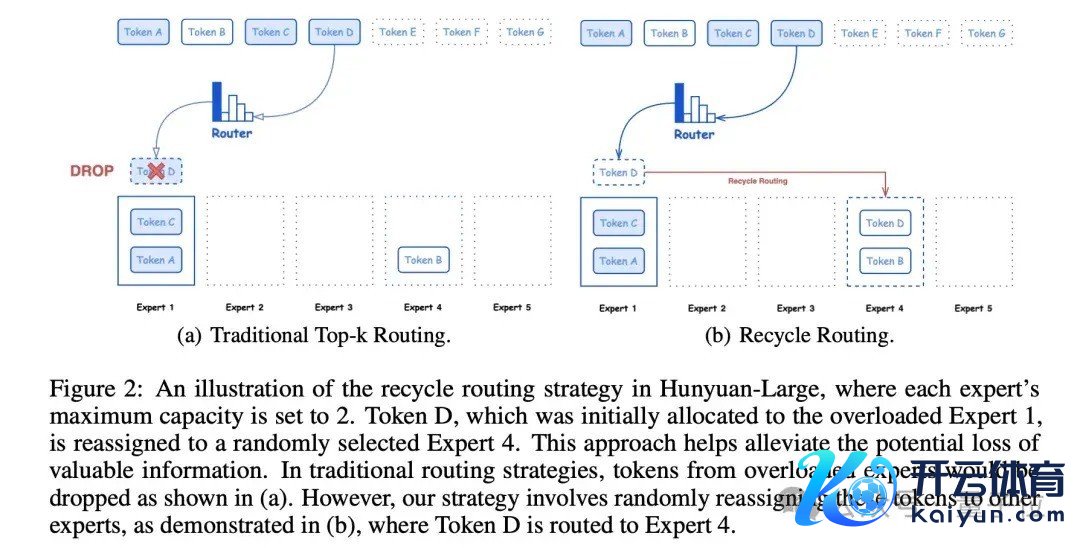
回收路由战略:
传统MoE常因巨匠超载而丢弃过多tokens。Hunyuan-Large筹画了巨匠回收机制,保抓相对平衡的负载,充分哄骗考研数据,保证模子的考研稳固性和拘谨速率。
巨匠特定学习率适配战略:
不同巨匠承载的tokens各别庞杂,应设定不同学习率,如分享巨匠使用较大的学习率,确保每个子模子灵验地从数据中学习并有助于全体性能。
高质料合成数据混元团队开发了一套完竣的高质料数据合成经过,主要包括四个风物:教导生成、教导进化、回答生成和回答过滤。
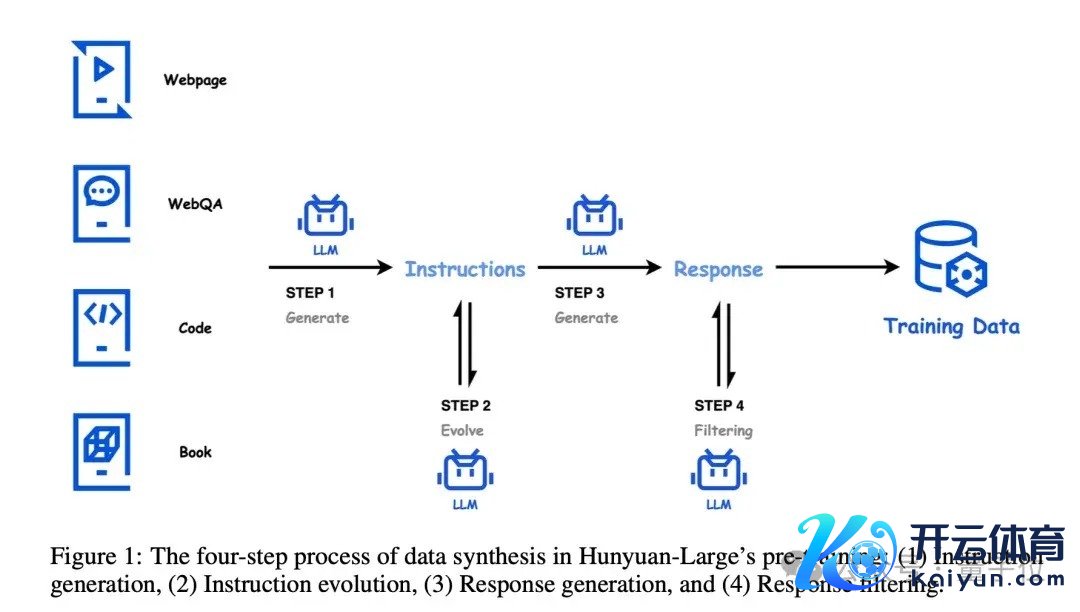
在教导生成阶段,混元团队使用高质料的数据源行动种子,遮蔽多个领域和不同复杂度,确保教导的各样性和全面性。
接下来是教导演化阶段,通过擢升教导的明晰度和信息量,推论低资源领域的教导,并冉冉擢升教导的难度,使得教导愈加丰富、精确和具有挑战性。
在回答生成阶段,混元团队接受成心的模子针对不同领域生成专科的谜底。这些模子在界限和筹画上各有不同,以确保生成的回答大约知足不同领域的条目。
临了是回答过滤阶段,混元团队接受critique模子对生成的回答进行质料评估,并进行自一致性查验,以确保输出的谜底是高质料的。
通过这四步合成经过,混元团队大约生成广泛高质料、各样化的教导-回答数据对,为MoE模子的考研提供了丰富、优质的数据维持。
这种数据合成方法不仅提高了模子的考研效果,也极地面促进了模子在多种卑劣任务上的发扬。
长文才略优化为了达成强盛的长文本贬责才略,混元团队在考研过程中接受了多项战略。
领先是分阶段考研,第一阶段贬责32K tokens的文本,第二阶段将文本长度膨胀至256K tokens。在每个阶段,都使用约100亿tokens的考研数据,确保模子大约充分学习和相宜不同长度的文本。
在考研数据的采选上,25%为当然长文本,如书本、代码等,以提供真确的长文本样本;其余75%为等闲长度的数据。这种数据组合战略确保了模子在取得长文交融才略的同期,也能保抓在等闲长度文本上的基础贬责才略。
此外,为了更好地贬责超长序列中的位置信息,混元团队对位置编码进行了优化。他们接受了RoPE位置编码方法,并在256K tokens阶段将base frequency膨胀到10亿。这种优化情势大约灵验地贬责超长序列中的位置信息,擢升模子对长文本的交融和生成才略。
除了在公开数据集上进行评测,混元团队还开发了一个名为”企鹅卷轴”的长文本评测数据集。
“企鹅卷轴”包含四个主要任务:信息抽取、信息定位、定性分析和数值推理。

不同于现存的长文本基准测试,”企鹅卷轴”有以下几个上风:
数据各样性:”企鹅卷轴”包含了各式真确场景下的长文本,如财务阐发、法律文档、学术论文等,最长可达128K tokens。任务全面性:数据集涵盖了多个难度档次的任务,构建了一个全面的长文本贬责才略分类体系。对话数据:引入了多轮对话数据,模拟真确的长文本问答场景。多话语维持:提供中英双语数据,知足多话语应用需求。推理加快优化为了进一步擢升Hunyuan-Large的推理效果,混元团队接受了多种优化时代,其中最要道的是KV Cache压缩。
主要蚁合了两种方法:GQA(Grouped-Query Attention)和CLA(Cross-Layer Attention)。
GQA通过开采8个KV head组,压缩了head维度的KV cache;而CLA则通过每2层分享KV cache,压缩了层维度的内存占用。
通过这两种战略的组合,混元MoE模子的KV cache内存占用缩小了约95%,而模子性能基本保抓不变。这种显贵的内存优化不仅大幅擢升了推理效果,也使得模子更易于部署,适配各式本色应用场景。

后考研优化
预考研的基础上,混元团队接受了两阶段的后考研战略,包括监督微调(SFT)和东说念主类反馈强化学习(RLHF),以进一步擢升模子在要道领域的才略和东说念主类对王人进程。
在SFT阶段,混元团队使用了卓越100万条高质料数据,遮蔽了包括数学、推理、问答、编程等多个要道才略领域。为了确保数据的高质料,团队接受了多重质料罢休设施,包括法例筛选、模子筛选和东说念主工审核。系数这个词SFT过程分为3轮,学习率从2e-5衰减到2e-6,以充分哄骗数据,同期幸免过拟合。
在RLHF阶段,混元团队主要接受了两阶段离线和在线DPO蚁合。离线考研使用事先构建的东说念主类偏好数据集,以增强可控性;在线考研则哄骗刻下战略模子生成多个恢复,并用奖励模子选出最好恢复,以提高模子的泛化才略。
同期,他们还使用了指数滑动平均战略,缓解了reward hacking问题,确保了考研过程的幽闲和拘谨。
One More Thing在发布会现场,腾讯混元大模子算法崇敬东说念主康战辉还暴露,Hunyuan-Large之后,还会谈判冉冉开源中袖珍号的模子,相宜个东说念主开发者、边际侧开发者的需求。

另外腾讯同期开源的3D大模子可移步这里了解。
官网:
https://llm.hunyuan.tencent.com/Github地址:https://github.com/Tencent/Tencent-Hunyuan-LargeHugging Face 地址:https://huggingface.co/tencent/Tencent-Hunyuan-Large参考勾搭:
[1]https://x.com/Thom_Wolf/status/1853694513585303771— 完 —
量子位 QbitAI · 头条号签约
关爱咱们,第一时刻获知前沿科技动态
栏目分类